ES 核心概念
ElasticSearch:简称 es,分布式全文搜索引擎。实时的存储、检索数据。
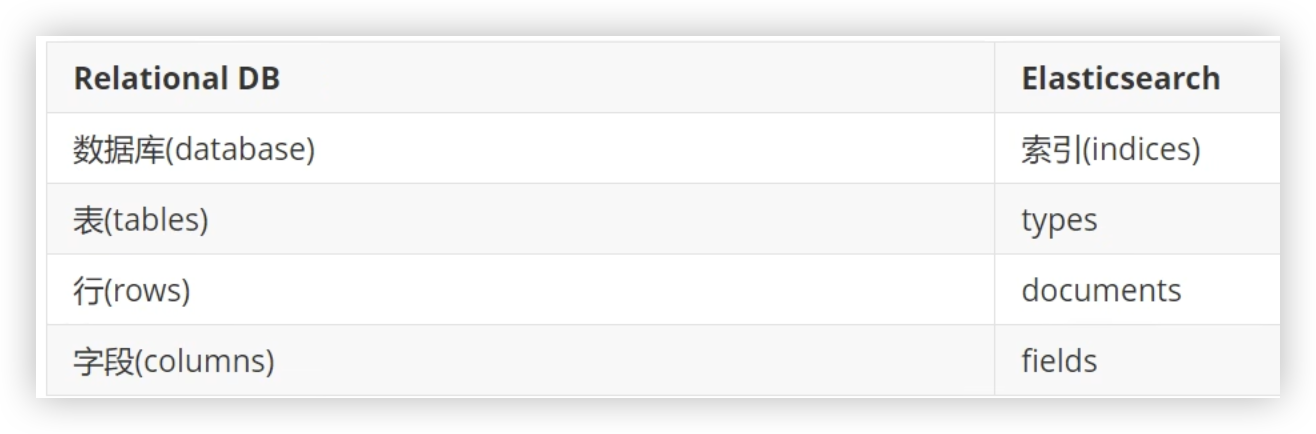
索引就是数据库,文档就是一条条数据
倒排索引
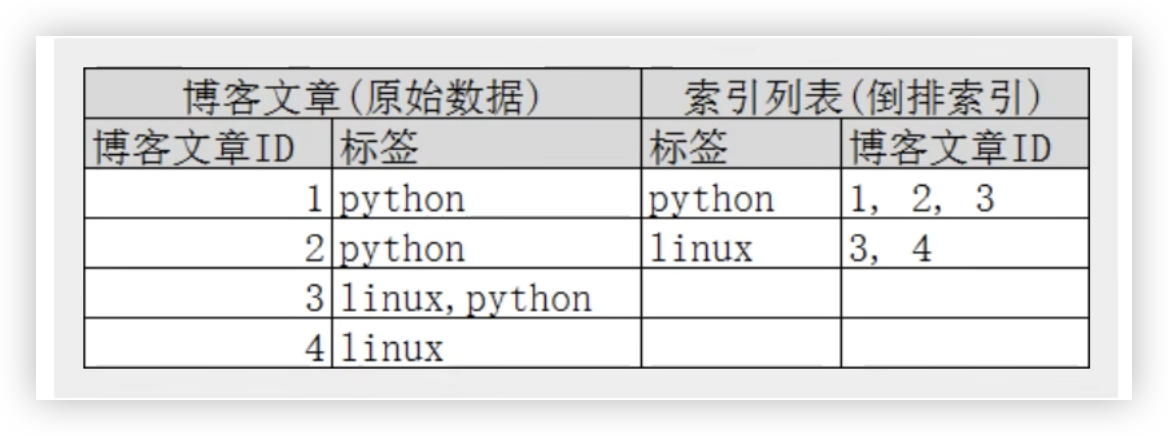
将文章中的标签都取出来,有该标签的文章则记录下来。以后查询时,只需要查看标签,获取掉对应的文章,过滤掉无关的文章。
IK 分词器
IK 提供了两个分词算法:ik_smart 和 ik_max_word,前者为最少切分,后者为最细粒度切分。
ik_smart 会讲句子切分成词语,词语不会彼此重叠。
ik_max_word 会按细粒度切分,也就是前后只要能组成词语就切分,不在乎是否重叠。
Rest 分格
关于索引的基本操作
基础测试
1、创建一个索引
PUT /索引名/类型名/文档id
{
键值对形式
}添加数据
PUT /test3/_doc/1
{
"name": "wdcp",
"age": "13",
"birth": "2001-01-05"
}更新数据
# 使用 POST 更新数据, 使用_update
POST /test3/_doc/1/_update
{
"doc": {
"name": "大盘"
}
}如果不使用 _update,改动一个数据需要把其他的值也写上,否则更新后为空。
关于文档的基本操作(重点)
基本操作
GET test3/_doc/_search?q=name:大盘模糊查询
GET test3/_doc/_search
{
"query": {
"match":{
"name": "大盘"
}
}
}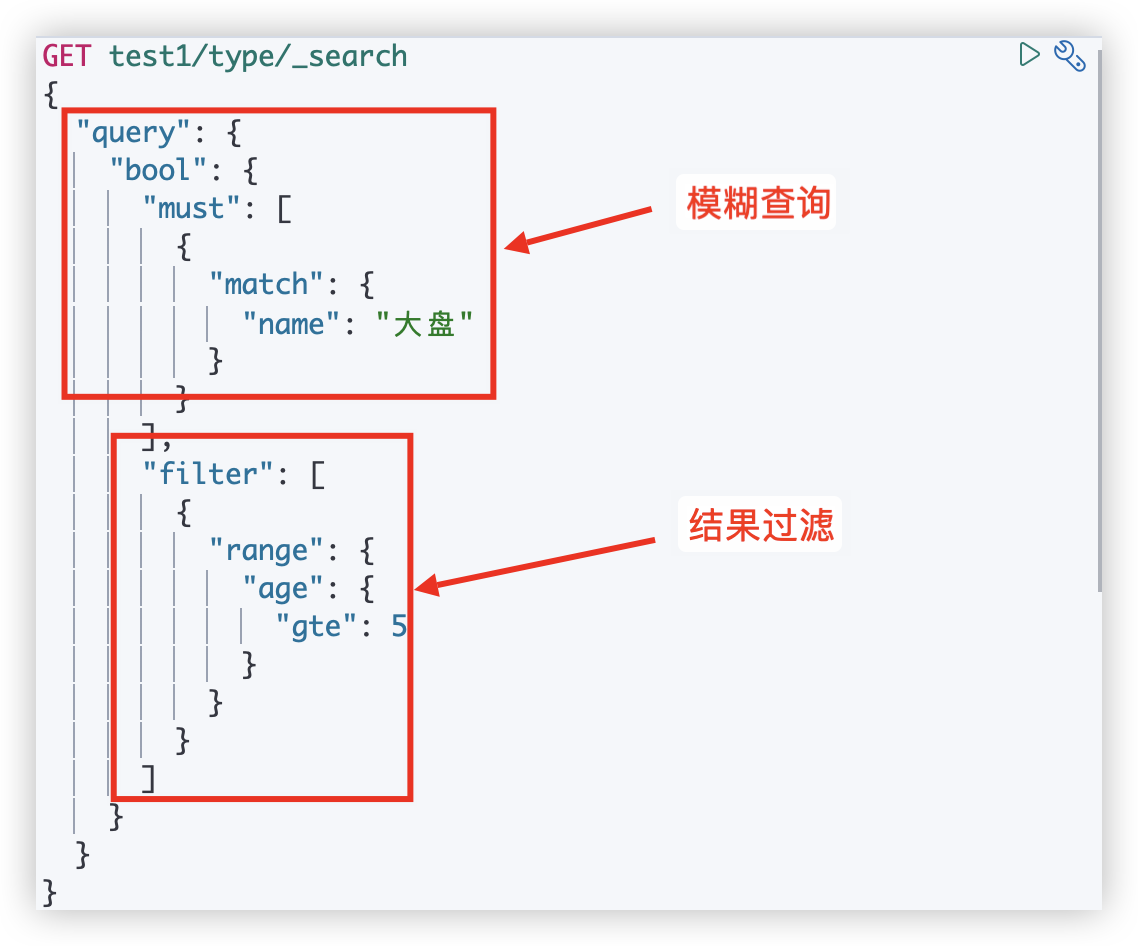
- gt 大于
- gte 大于等于
- lt 小于
精确查询
term 是通过倒排索引精确的查找!
关于分词:
- term
- match:会进行分词,再查询
两个类型 text keyword

对于 keyword,查询时不会被分词,因此只有全局匹配才查到。对于 text 会被分词。
高亮
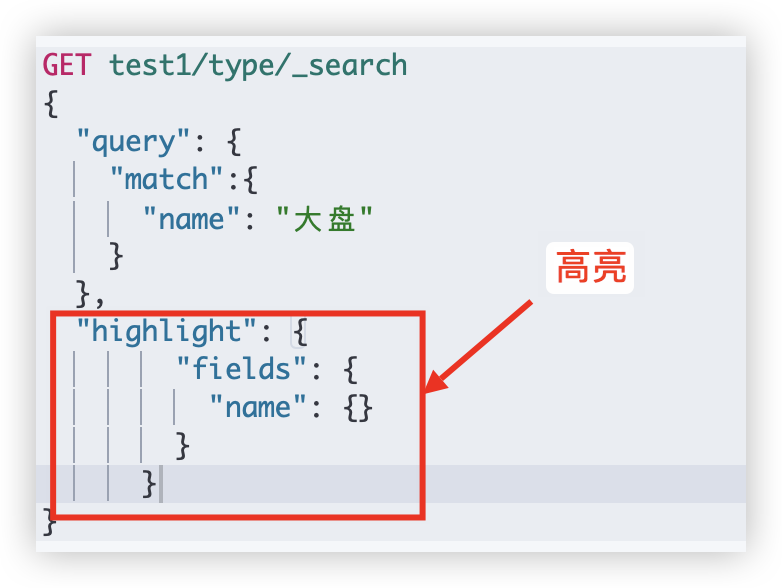
原理
倒排索引:比如某个文档经过分词,提取了 20 个关键词,为每一个词建立一个索引,指明该词在文章中出现的次数和位置。倒排索引就是关键词到文档ID的映射。
index:类似于 MySQL 的表。
document:类似于 MySQL 的记录。
text与keyword:keyword的类型是不会分词的,只能通过精确匹配查询到。text会先分词,根据分词的内容建立倒排索引。
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1216271933@qq.com

