Redis 在项目中的应用
Redis 为什么快
大部分操作在内存中完成
采用单线程避免了多线程的竞争切换开销
Reids 使用 I/O 多路复用来处理大量的 Socket 请求,epoll 因此单线程就可以管理多个 I/O 连接。
1、做缓存
删除缓存还是更新缓存:删除缓存。更新缓存有两个问题:在更新了数据库之后,但还没来得及更新缓存,此时用户访问的是脏数据;相比之下,删除缓存机制会将缓存删除,当下次访问时,从数据库查找最新的数据并更新缓存。此外,如果数据频繁更新,缓存也要频繁更新,只有最后一次更新才有效,这就导致性能开销,很多都是无效更新。
先操作缓存,还是先操作数据库? 先操作数据库,再删除缓存。如果先删除缓存,再操作数据库,在多线程情况下,线程 A 删除缓存后,数据库更新很慢;在数据库未更新完成时,线程 B 趁虚而入,读取数据库的脏数据并写入缓存。而先更新数据库,再删除缓存,出现数据不一致的概率小。
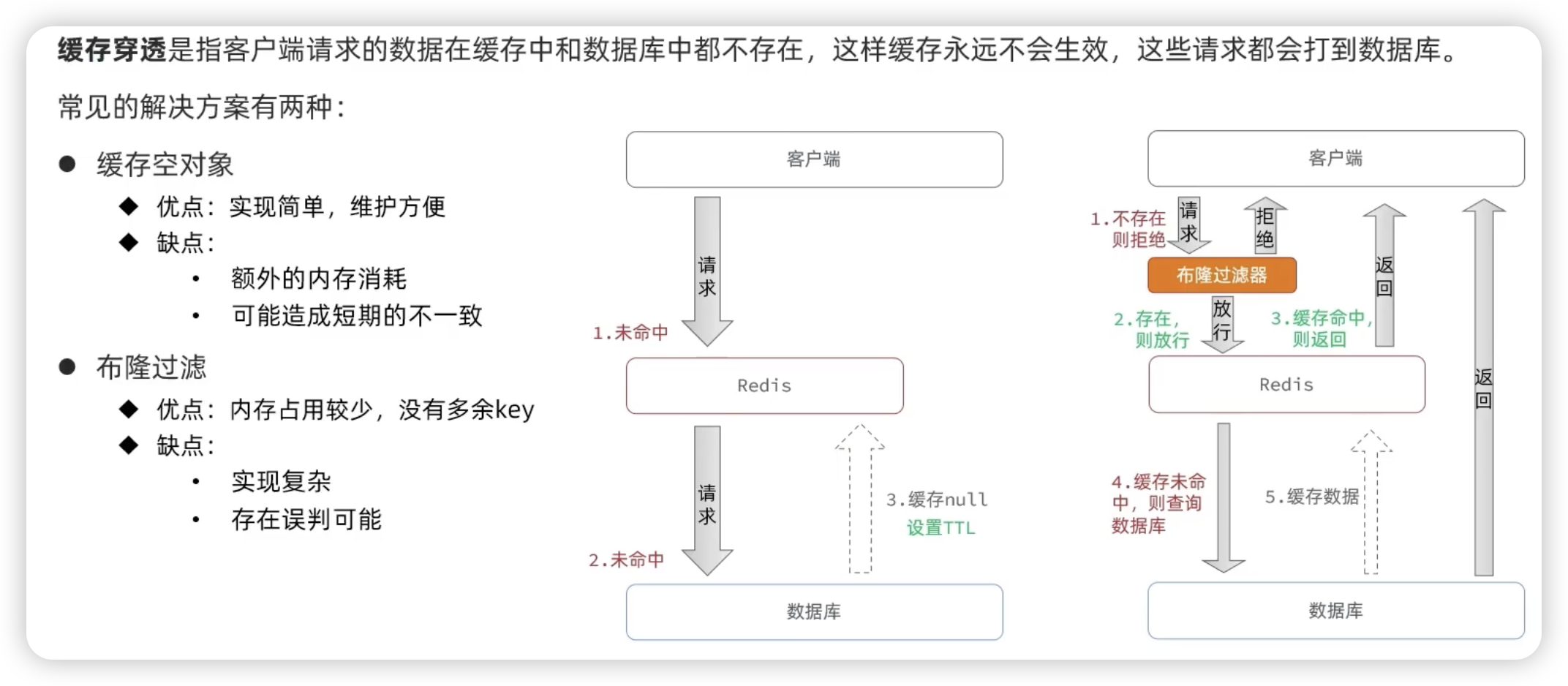
缓存穿透
客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,这些请求都会打到数据库。
一般有两种情况:
- 缓存中的数据或数据库中的数据被误删除了。
- 恶意攻击
设置空值
解决方案:缓存 null 并设置空值。
缺点:可能造成短期的不一致。可以当插入一条数据时,主动将这条数据插入到缓存中覆盖之前的null。
布隆过滤
缓存击穿
某个热点数据过期了,在这个数据缓存重建之前,有大量请求同时查询这个数据,这些请求就直接打到数据库上,给数据库带来巨大的冲击。
解决方案:1、互斥锁 2、设计逻辑过期
互斥锁实现逻辑:先根据 key 在缓存中查找,找到直接返回。如果是空值,说明发生了缓存穿透,返回空。这里起初用的是自定义的锁:SETNX。只有当 key 不存在时才会成功,如下
// private boolean tryLock(String key) {
// Boolean aBoolean = stringRedisTemplate.opsForValue().setIfAbsent(key, "1", LOCK_SHOP_TTL, TimeUnit.SECONDS);
// return BooleanUtil.isTrue(aBoolean);
// }
// private void unLock(String key) {
// stringRedisTemplate.delete(key);
// }如果获取锁失败,休眠一段时间,重新查询。获取锁成功后,在数据库查询,如果未查到则发生了缓存穿透,插入空值。如果查到了则存入 redis,最后释放锁。
互斥锁解决缓存击穿主要在于先让一个线程获取锁,将其他线程阻止在外,此线程在数据库查询一次后存入缓存,外面的线程就可以从缓存中取数据,不用都来访问数据库。
逻辑过期实现逻辑:缓存过期策略意思是在商品中添加一个逻辑过期时间字段,在查询之前就预加载到了缓存,如果没有查到,说明该商品不是活动商品。如果查到的话,将其转化为对应的 Bean 对象,判断其逻辑时间是否过期(缓存过期时间在当前时间之后则尚未过期),如果未过期直接返回这个对象;否则需要开启独立线程获取锁查询数据库,并重新写入缓存,而主线程直接返回旧的缓存。
这样做是为了保证响应速度,缓存数据虽然可能稍微落后于数据库的最新数据,但是在大多数情况下,这个小小的延迟并不会影响系统的功能和用户的体验。逻辑过期一定要先进行数据预热,将我们热点数据加载到缓存中。
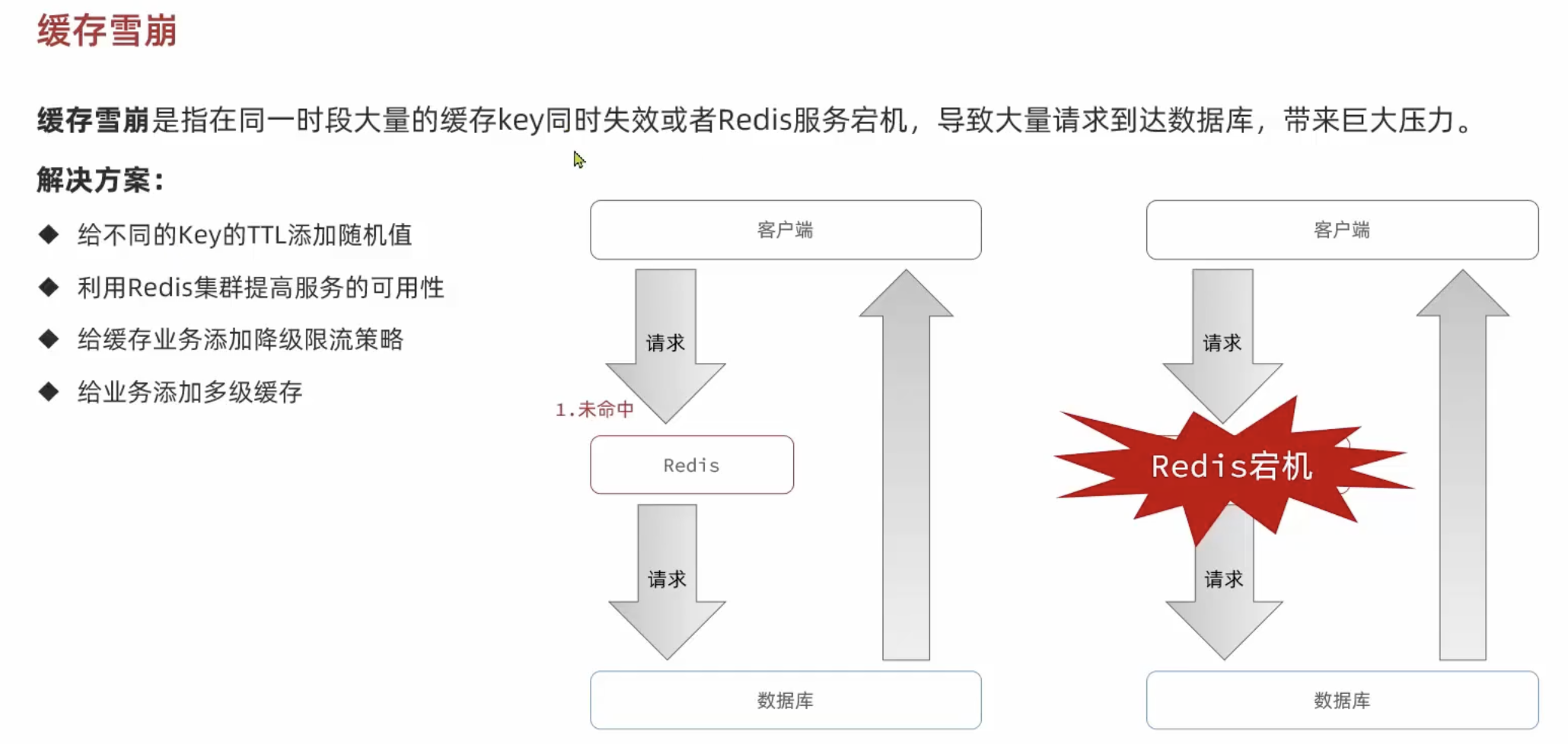
缓存雪崩
大量的缓存在同一时间失效或 redis 服务宕机,导致大量的请求都直接落到了数据库上,对数据库造成了巨大的压力。
解决方案:
避免将大量数据设置为同一个缓存时间(加个随机数)。
互斥锁
2、分布式锁
原理
SET 命令有个 NX 选项,用来实现分布式锁。当 key 不存在时,插入成功;存在则插入失败。
解锁时为了区分当前线程是否为获取锁的线程,需要先判断,再释放锁。这是两个操作,需要 Lua 脚本保证解锁的原子性。
超卖问题
一开始判断逻辑与创建订单是放到一起的,且没有加锁。这样就会出现超卖。
使用乐观锁解决。
为什么会发生超卖问题?多个线程在同时执行时,对库存的判断和扣减并不是原子性操作,可能导致同一时刻多个线程判断库存都是足够的,然后都执行了扣减库存的操作,从而导致超卖。
解决方案:
悲观锁:认为一定会有线程安全问题,每次操作数据库前都要获取锁。常见的悲观锁有:synchronized、lock。
乐观锁:认为不一定会有线程安全问题,因此不加锁,只是更新数据时判断有没有其他线程对数据做了修改。常见的有版本号、CAS。
CAS:不用额外对表加个版本号,用库存代替版本。首先读取当前的值,在执行 SQL 时,将要修改的字段值与读取的值进行比较,如果不同,说明这期间有其他线程修改了。说明有其他线程涉入修改,于是当前线程放弃修改。
但在项目中修改库存时,按理说只要库存大于 0 就可以减一,但在并发操作下用了 CAS 后,很多个请求都没有执行 SQL,为什么? 举个例子:库存初始为 100,线程1和线程2先后查询到库存为 100,线程1先买,库存减一,此时为 99。线程2此时买,发现库存不为原来查询的 100,就不更新了。改进:只要库存大于0,就可以更改。
一人一单
开始只是在判断逻辑中加了个订单的判断,但在并发情况下多个线程同时判断成立,于是就下了多次单。
上面的超卖问题是针对单体项目的,也就是单个用户进行购买,但实际需求中是一个用户只能限购一单,如何实现呢?
起初是多加了个判断:判断当前用户是否在数据库表中有记录了,有说明已经下过单了,但这样还是会一个人下多个单,为什么?还是并发问题,多个线程可能同时判断当前用户未下过单,于是同时操作数据库减库存。我们需要的是判断和操作数据库是一个原子操作。
单体模式下的解决方案:使用悲观锁,锁的是用户的 id.toString().intern(),不能直接锁 id,每次得到 id 都是新的对象,intern() 表示从常量池中寻找与字符串值一致的对象,这样就能保证同一用户请求时,只有一个用户进入锁中。但这种方式锁住的是当前 JVM 中的对象,集群下有多个 JVM,因此我们需要分布式锁。
我们通过 nginx 的负载均衡启动 2 台服务器模拟,本地锁 synchronized 会失效,我们需要使用分布式锁。分布式锁的实现用 redis 的 setnx 实现,也就是我们自定义锁替换掉 synchronized。但还有几个问题,1、多个线程如何判断释放的锁是否是自己的呢?
这里可以给锁拼接上 uuid,增加锁标识的复杂性,释放锁时需要先判断锁存在,再删除锁。2、如果获取锁成功后发生了堵塞,锁超时释放了,此时有其他线程获取了锁,而之前的那个线程堵塞完成,又把锁释放了。
问题:判断锁后如果发生了堵塞,其他线程获得锁,堵塞完后之前的线程直接释放锁了。这是因为判断锁和释放锁中间的堵塞。
这里我们将判断锁和释放锁打包为 lua 脚本,具有原子性。
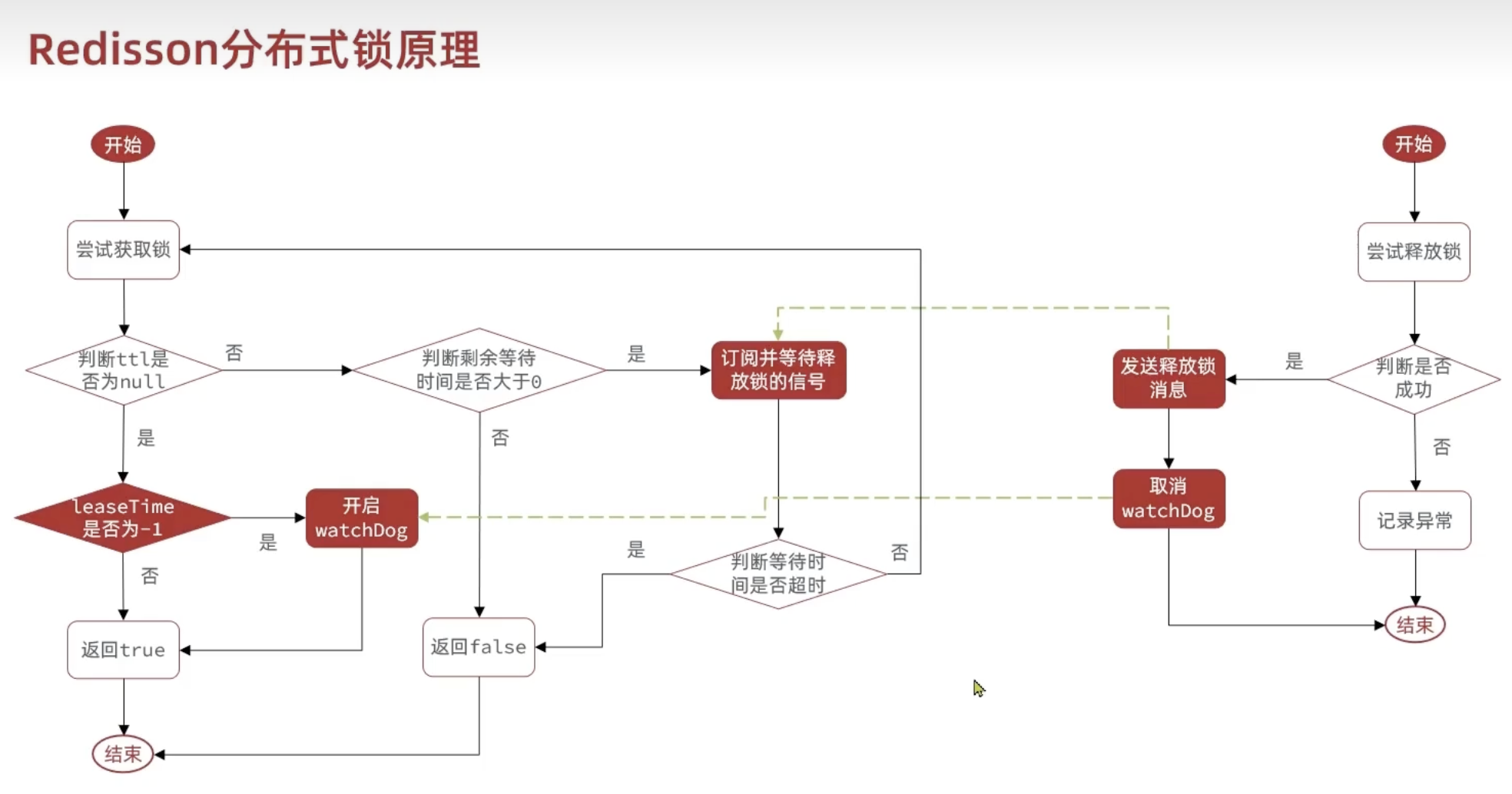
但我们自定义的锁总有缺陷,如锁不可重入、不可重试等,我们使用 Redssion 框架。
最终优化:将库存判断、用户是否下单 这些逻辑判断写到一个 lua 脚本中,只有都通过了再使用消息队列 插入订单,执行库存减一。实现解耦合。
3、lua脚本异步操作
之前的业务是判断库存后通过分布式锁实现一人一单,这是串行操作,效率不高,其实判断库存、一人一单与操作数据库可以隔离开,如果用户有资格下单,就可以返回订单号了,用户不需要等待数据库操作完成即可获得反馈。
此外,我们在保存优惠券时就可以把优惠券信息存入缓存,在查询用户是否有资格下单时,直接从缓存中查库存就好,并且将购买的用户写入缓存,避开了直接访问数据库。
4、Sorted Set 维护点赞排行榜
- 在首页如何判断当前用户是否给某个博客点过赞?这是用 redis 实现的,用户点赞都放到了缓存中,为了实现点赞排行榜,使用的是 zset 数据结构。每次访问首页时,查询缓存中是否有用户点赞的缓存,有的话就设置 isLike 为 true,在前端就会高亮显示。
原理
数据结构的应用场景
1、String:存对象、分布式锁、计数器、验证码
2、hash:对象、购物车
3、List:存储热点数据
4、Set:点赞、共同关注
5、ZSet:排序,排行榜
hash和String存储对象:当只需要读取对象的某一个字段,String会将整个对象反序列化再读取,hash就很方便。
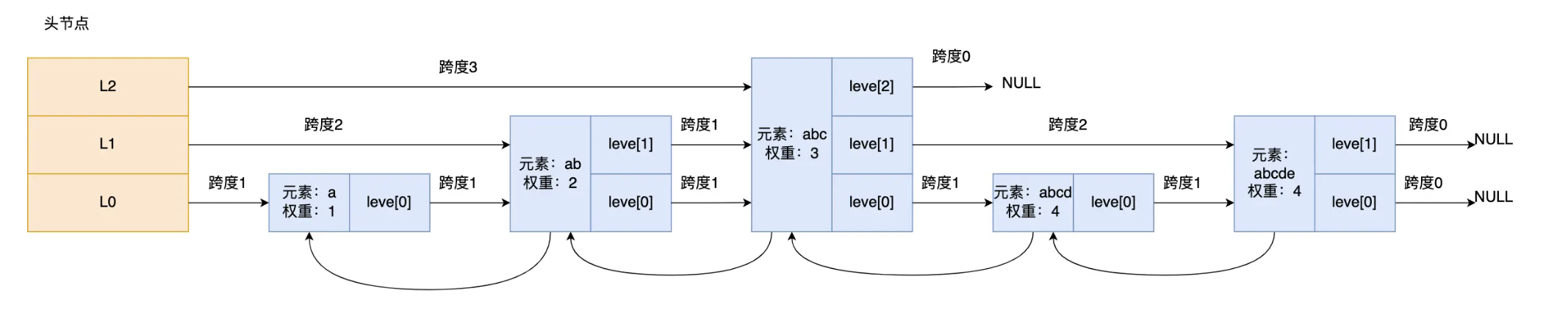
Zset的底层如何实现
跳表查找原理:根据权重和值
Redis 持久化
RDB 快照:将某一时刻的内存数据,以二进制的方式写入磁盘;
AOF 日志:每执行一条写操作命令,就把该命令以追加的方式写入到一个文件里;
混合持久化方式:Redis 4.0 新增的方式,集成了 AOF 和 RBD 的优点;
RDB快照
主进程调用 fork 创建子进程,主进程和子进程共享同一物理内存,但是途中主进程处理了写操作,修改了共享内存,于是当前被修改的数据的物理内存就会被复制一份。
AOF 日志
执行完一条写操作后,将写命令以追加的方式写入文件,然后Redis重启时就会读取这个文件目录的命令,逐一执行命令的方式来数据恢复。
Redis 过期删除
常用的过期删除策略是惰性删除、定期删除、定时删除。
- 惰性删除:只有访问这个键时才检查是否过期。
- 定期删除:默认情况下Redis每秒检测10次, 检测的对象是所有设置了过期时间的键集合,每次从这个集合中随机检测20个键查看他们是否过期,如果过期就直接删除,如果过期的key比例超过1/4,那就把上述操作重复一次(贪心算法)。
- 定时删除:为每个设置过期时间的key都创造一个定时器,到了过期时间就清除。
redis 使用的是惰性删除策略和定期删除策略。
内存淘汰机制
Redis 4.0前有 6 种淘汰策略。
- volatile-lru:当Redis内存不足时,会在设置了过期时间的键中使用LRU算法移除那些最少使用的键。(注:在面试中,手写LRU算法也是个高频题,使用双向链表和哈希表作为数据结构)
- volatile-ttl:从设置了过期时间的键中移除将要过期的
- volatile-random:从设置了过期时间的键中随机淘汰一些
- allkeys-lru:当内存空间不足时,根据LRU算法移除一些键
- allkeys-random:当内存空间不足时,随机移除某些键
- noeviction:当内存空间不足时,新的写入操作会报错
前三个是在设置了过期时间的键的空间进行移除,后三个是在全局的空间进行移除
在Redis4.0后可以增加两个
- volatile-lfu:从设置过期时间的键中移除一些最不经常使用的键(LFU算法:Least Frequently Used))
- allkeys-lfu:当内存不足时,从所有的键中移除一些最不经常使用的键
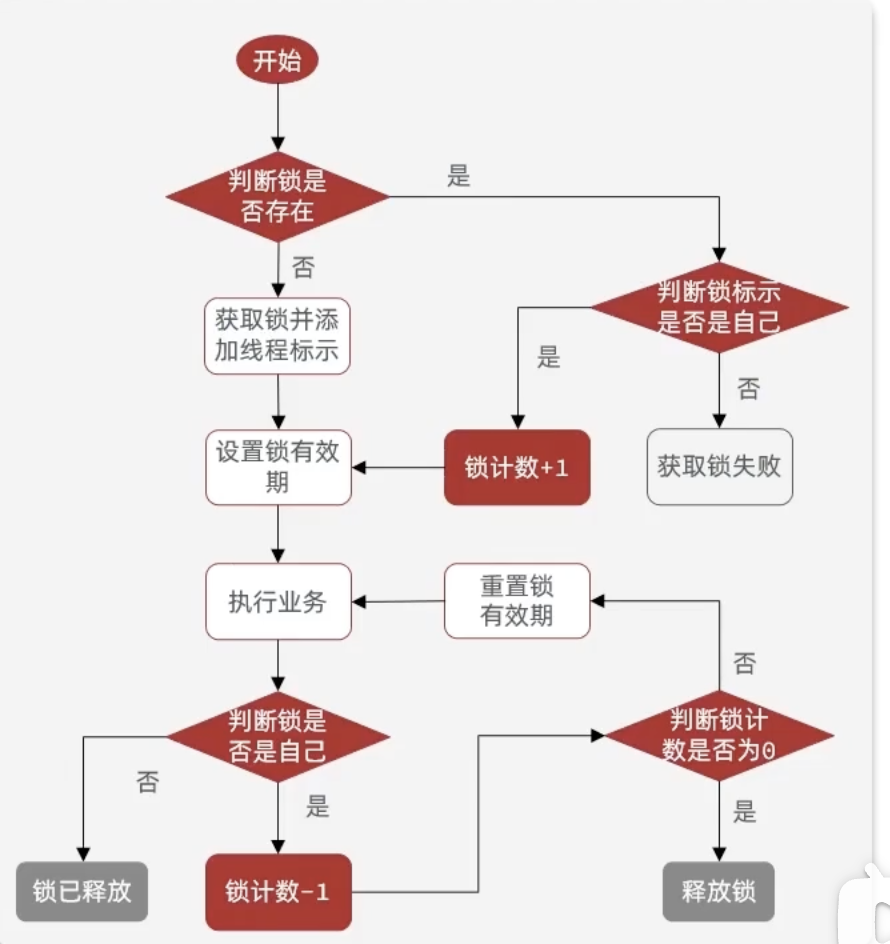
Redisson 原理
可重入原理

转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 1216271933@qq.com

